Creazione di una pipeline
La creazione di una pipeline inizia nella dashboard cliccando sul pulsante CREATE NEW: si apre una modale che permette di inserire nome, descrizione e business island della nuova pipeline da creare.
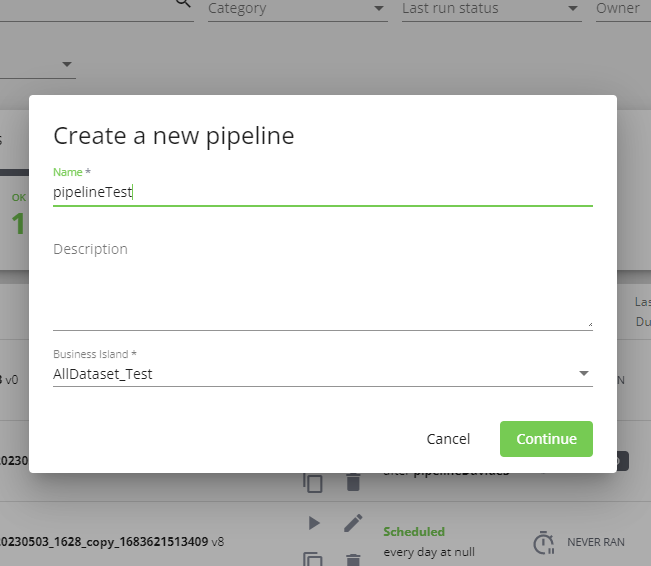
Nome e business island sono obbligatori e non potranno essere modificati in seguito, la descrizione è opzionale e può essere modificata successivamente. Due pipeline non possono avere lo stesso nome: il nome viene verificato e se corrisponde a quello di una pipeline già esistente viene visualizzato un messaggio di errore e non è possibile proseguire.
Cliccando su Continue si entra nella pagina di edit della pipeline, inizialmente vuota.
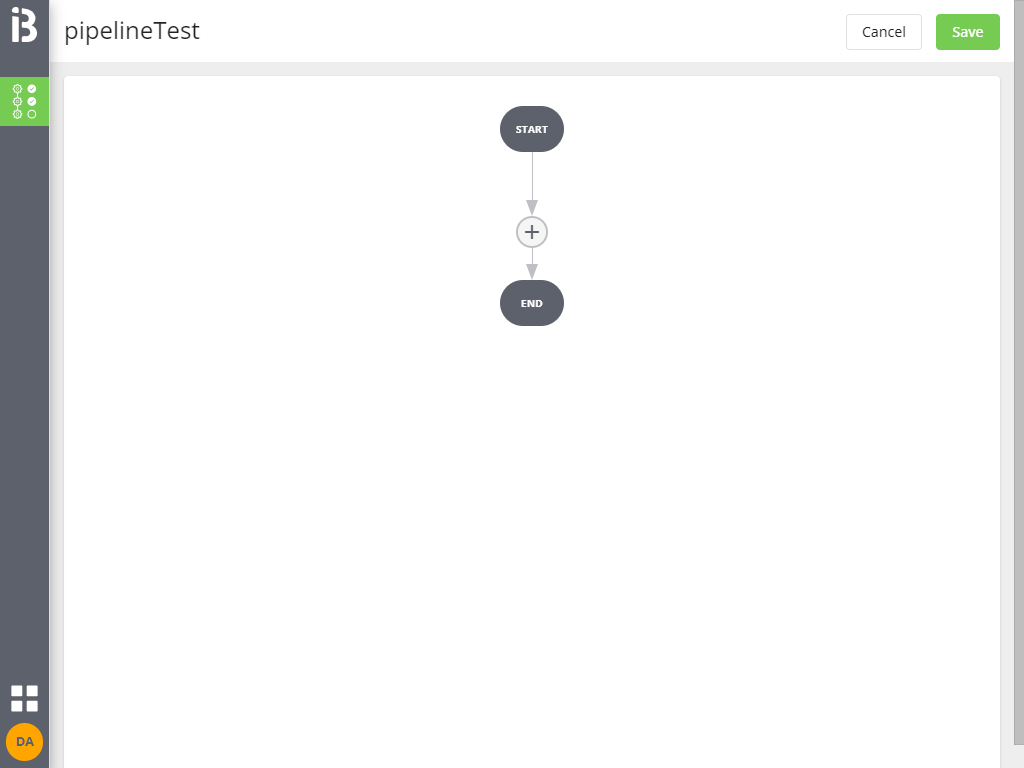
Non è possibile salvare la pipeline se non si aggiunge almeno un job.
Aggiunta e configurazione di un job singolo
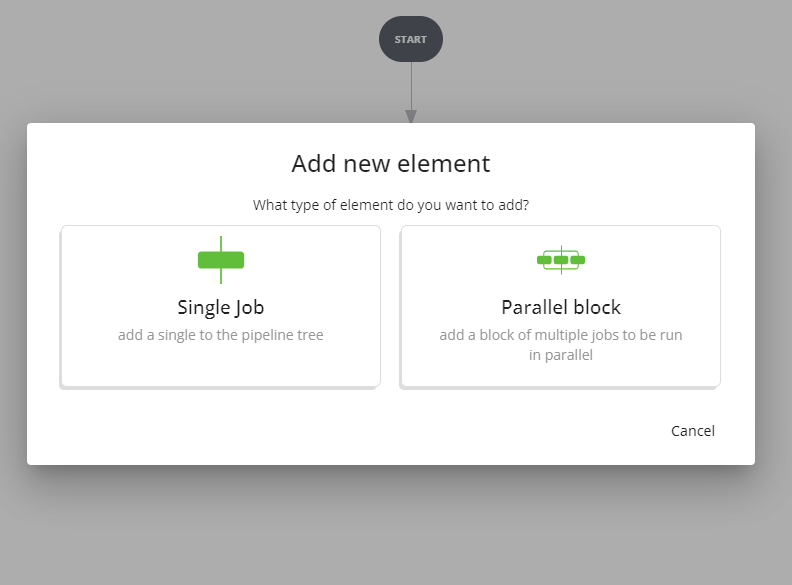
Cliccando sul + si apre la modale per l'aggiunta di un nuovo elemento, offrendo la scelta tra job singolo e blocco di job da eseguire in parallelo.
Selezionando Single job si passa alla selezione del job da inserire. L'elenco dei job disponibili è filtrato per tipo e opzionalmente per nome (cliccando sulla i si apre il dettaglio del job in una nuova scheda del browser). Sono mostrati solo job della business island associata alla pipeline e solo appartenenti ai moduli a cui l'utente ha accesso.
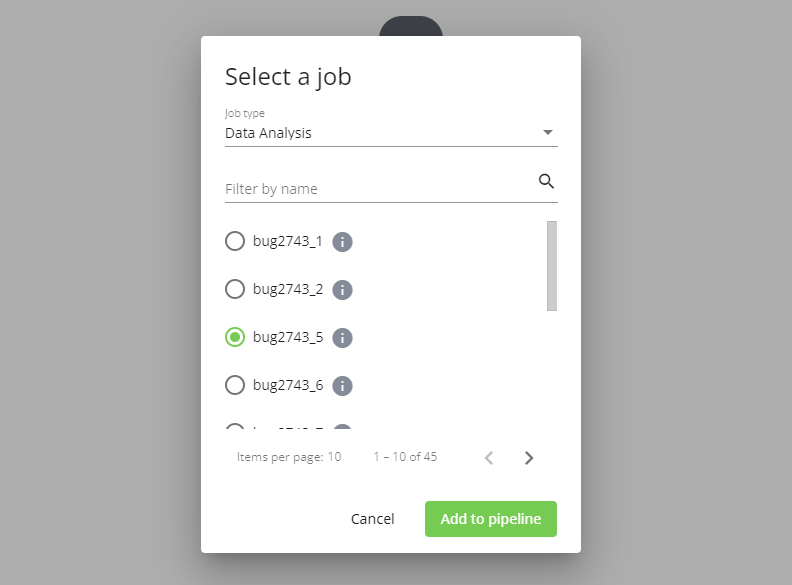
Selezionando un job e cliccando Add to pipeline questo viene aggiunto alla pipeline e si passa alla sua configurazione.
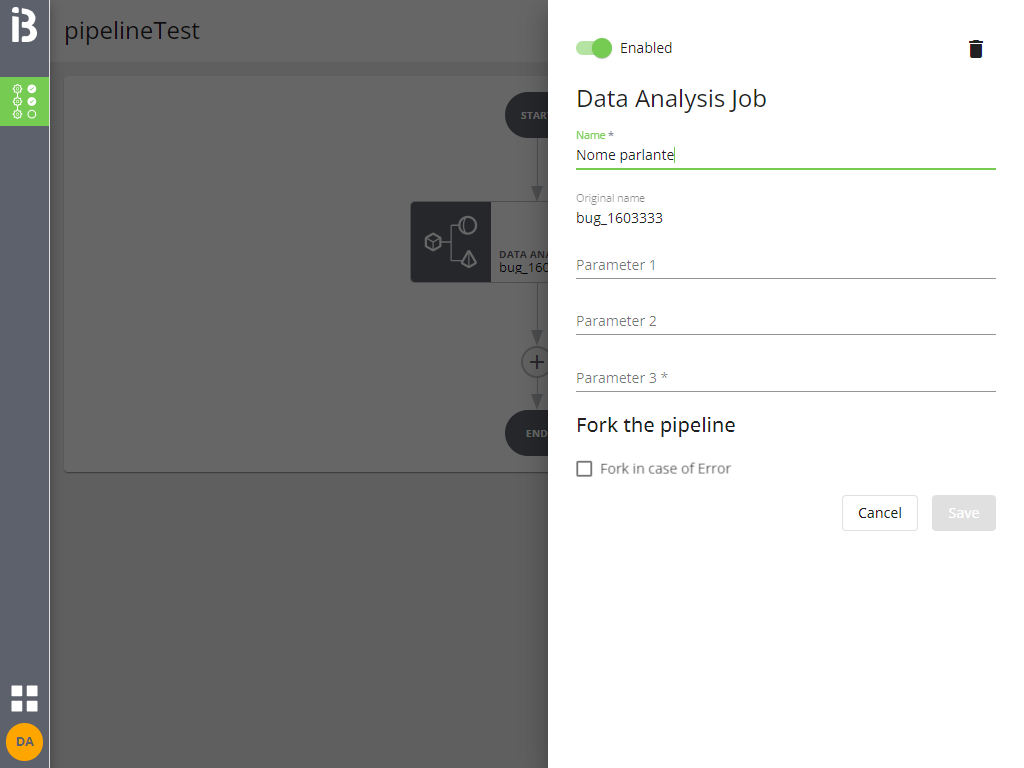
È possibile assegnare un nome al job (il nome è un alias valido solo all'interno di questa pipeline, di default è pari al nome del job originale che viene comunque mostrato) e inserire gli eventuali parametri di lancio.
Cliccando su Save si applicano le modifiche (ma la pipeline non è ancora salvata).
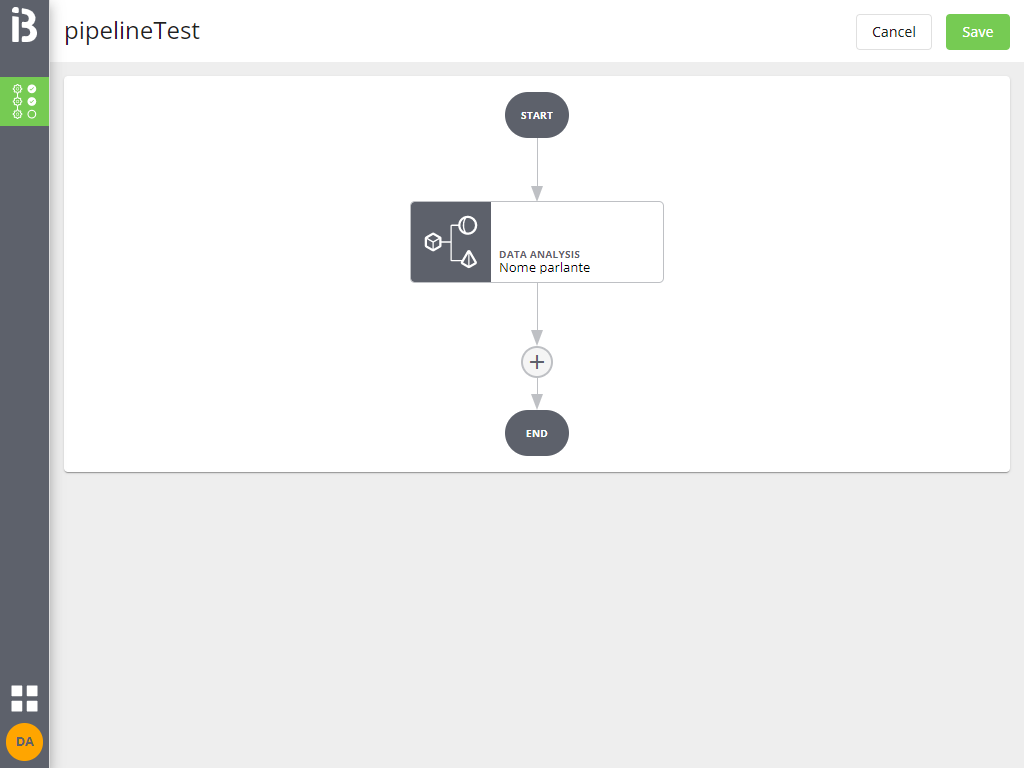
Cliccando sul job inserito si riapre l'interfaccia di configurazione da cui è possibile modificare nome e parametri inseriti.
Cliccando sull'icona + nel grafo è possibile inserire un altro job con le stesse modalità.
Aggiunta e configurazione di un blocco di job in parallelo
Oltre a job singoli è possibile inserire blocchi di elaborazione in parallelo.
Tutti i job contenuti all'interno del blocco verranno eseguiti in parallelo. Se anche uno solo dei job contenuti va in errore l'intero blocco parallelo sarà considerato in errore ma l'esecuzione degli altri job verrà comunque portata a termine.
Eventuali job successivi nella pipeline verranno eseguiti solo quando tutti i job contenuti nel blocco parallelo avranno terminato la loro esecuzione.
Cliccando sul + si apre la modale per l'aggiunta di un nuovo elemento, offrendo la scelta tra job singolo e blocco di job da eseguire in parallelo.
Selezionando Parallel block si passa alla selezione dei job che saranno contenuti all'interno del blocco. È possibile selezionare solo blocchi di elaborazione (sono quindi esclusi job di data quality e data matching).
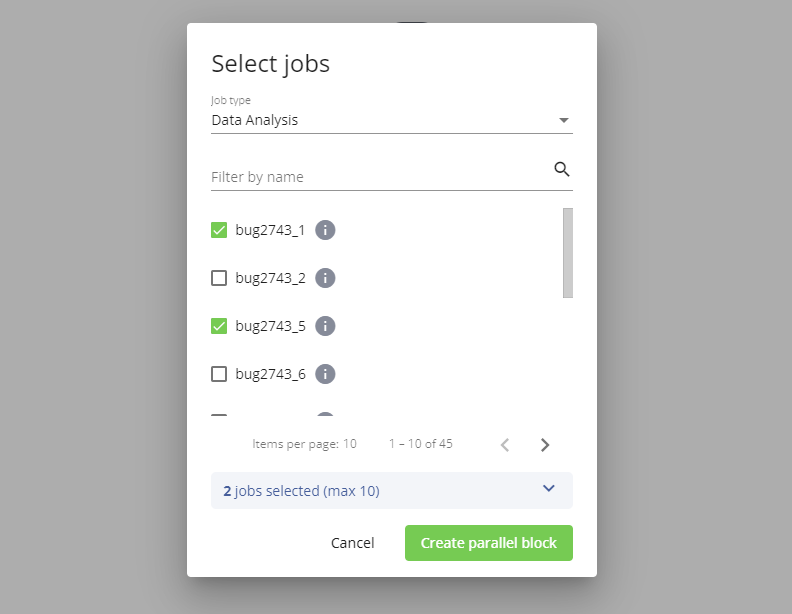
In basso è indicato il numero di job selezionati (è obbligatorio selezionarne almeno uno) e il limite massimo di job selezionabili, cliccando sull'indicazione o sulla freccia si espande il box mostrando i job attualmente selezionati (con la possibilità di deselezionarli). Anche qui la i permette di aprire il dettaglio del job in una nuova scheda del browser.
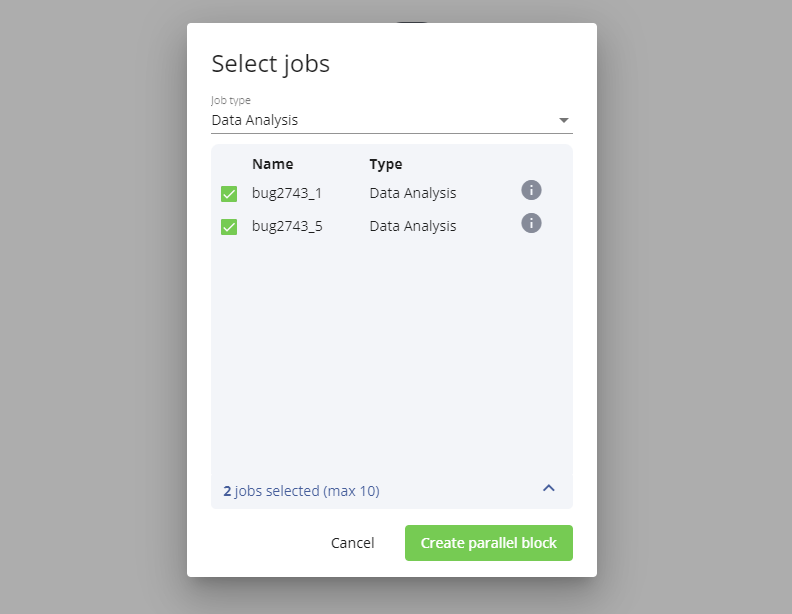
È possibile assegnare un nome al blocco parallelo, configurare i singoli job e modificare l'elenco dei job contenuti (cliccando su Add new +).
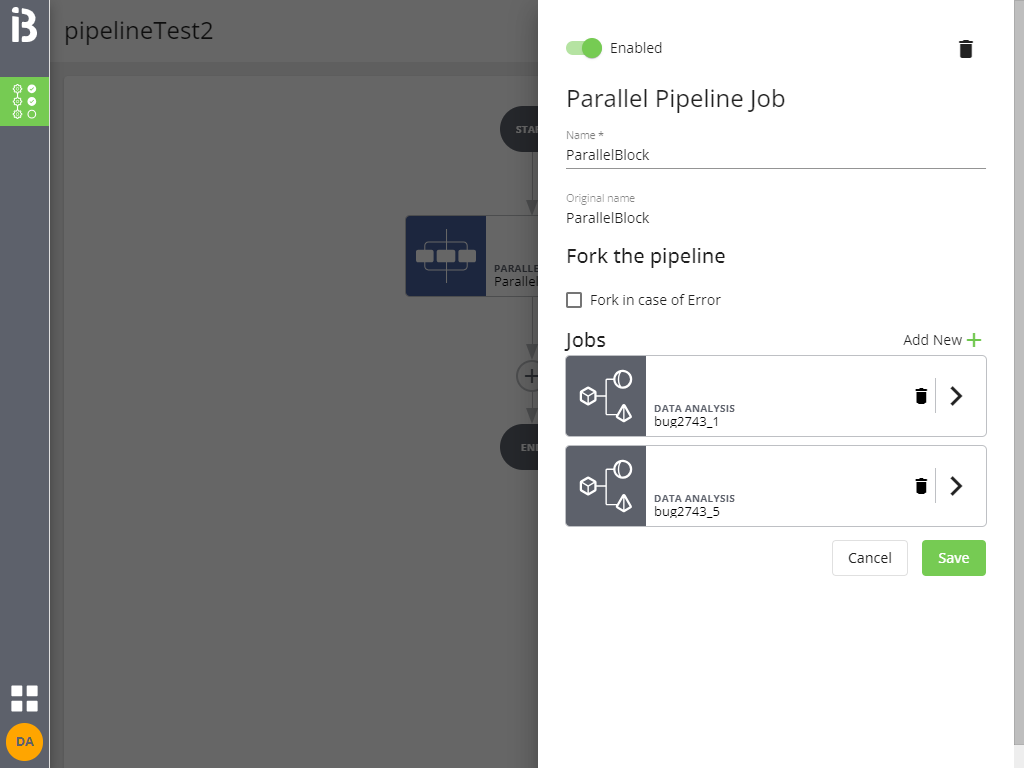
Cliccando su Save si applicano le modifiche (ma la pipeline non è ancora salvata).
Fork del flusso di esecuzione
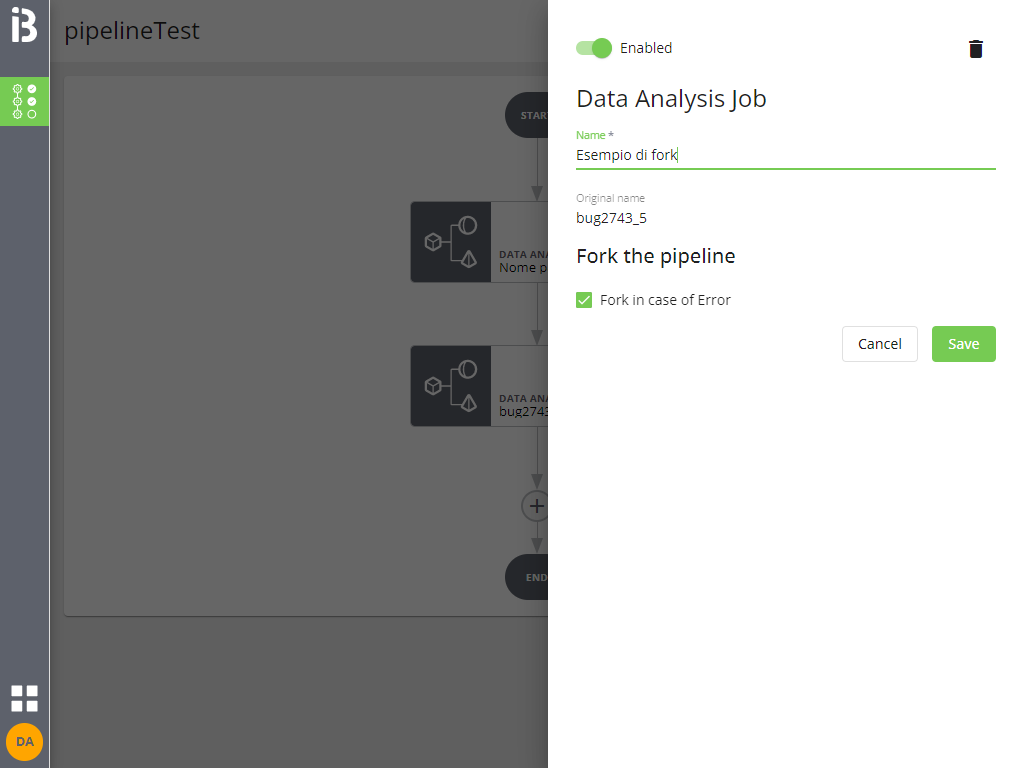
Tutti i job e i blocchi di job in parallelo permettono di creare un fork in caso di ERROR: in tal modo, in caso di errore, verranno eseguiti altri job (o conclusa l'esecuzione, ma senza generare un ERROR come esito finale).
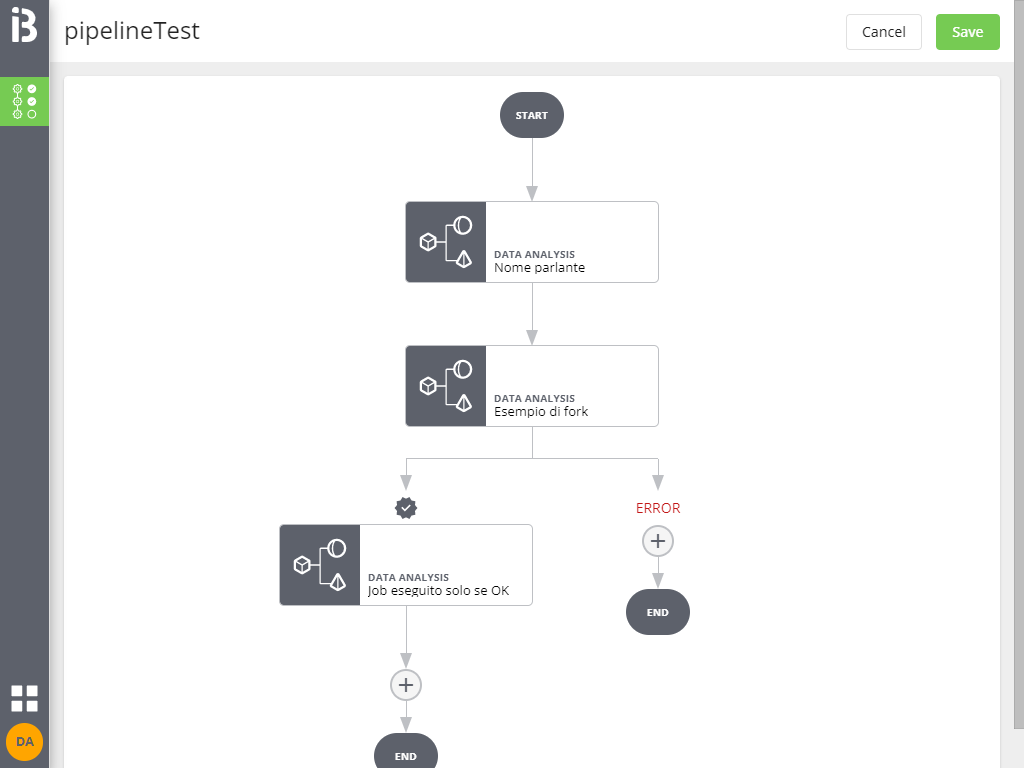
Le possibilità di fork dipendono dal tipo di job selezionato:
- per tutti i tipi di job e i blocchi di job in parallelo è possibile forcare in caso di errore
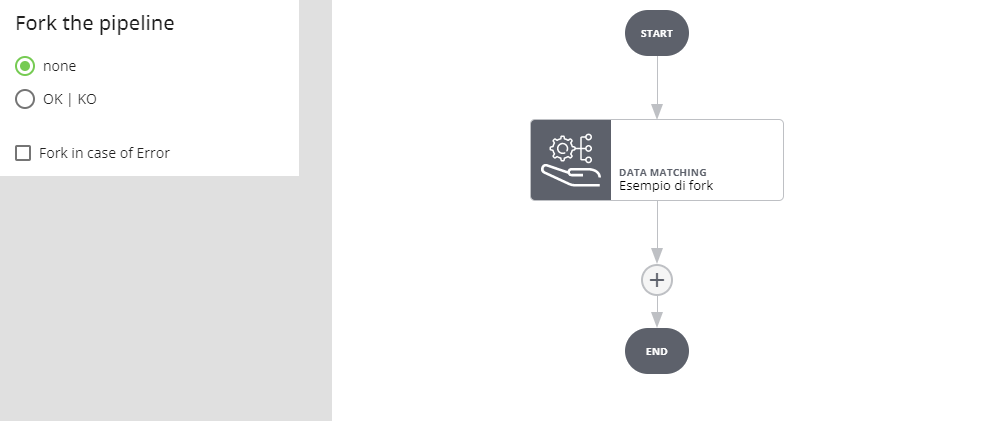
- per i job di Data Matching è possibile anche forcare per OK e KO
- per i job di Data Quality è possibile anche forcare per OK, KO e warning
È possibile modificare il tipo di fork solo se non sono ancora stati inseriti job nei sottorami derivanti dal fork stesso.
Come si comporta il fork?
Nel caso di blocco parallelo il fork si applica all'intero blocco: se anche uno solo dei job contenuti va in errore l'intero blocco è considerato in errore. Sia nel caso OK che nel caso ERROR gli elementi successivi della pipeline vengono eseguiti solo quando tutti i job contenuti nel blocco parallelo hanno terminato la loro esecuzione.
Error e KO
Il concetto di KO è diverso da quello di ERROR: KO nel caso di Data Matching e Data Quality indica che il job ha terminato correttamente la sua esecuzione e l'esito dei controlli è negativo, ERROR indica invece che un job non ha potuto portare a termine la sua esecuzione per problemi tecnici.
Fork per tutti i job (tranne Data Matching e Data Quality) e blocchi paralleli
Nessun fork
In caso di errore nell'esecuzione del job o del blocco l'esecuzione della pipeline si interrompe e va in stato ERROR
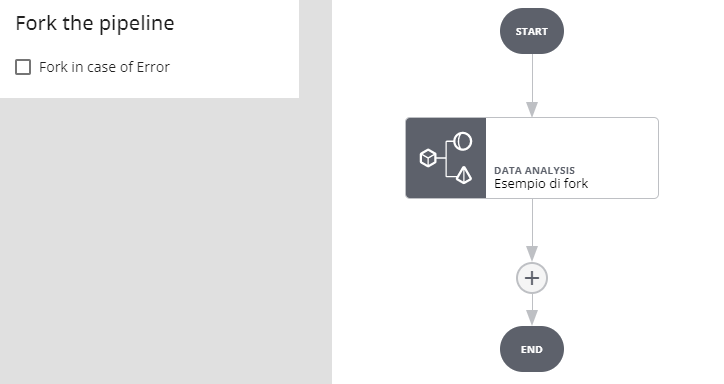
Fork in caso di errore
Se l'esecuzione del job o del blocco va a buon fine si prosegue per il ramo OK, in caso di errore si procede per il ramo ERROR
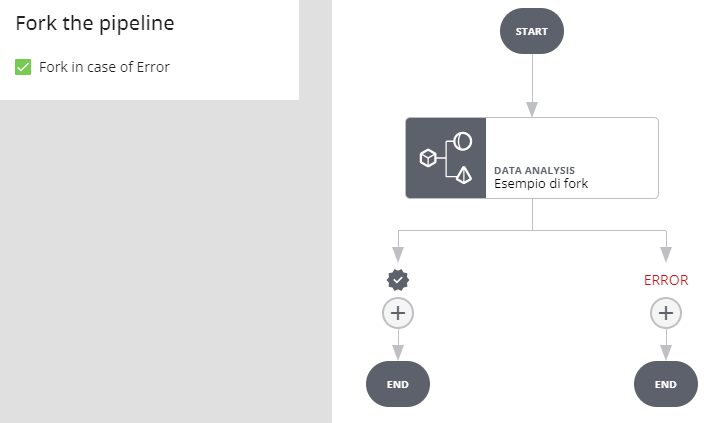
Fork per i job di Data Matching
Nessun fork
In caso di errore nell'esecuzione del job l'esecuzione della pipeline si interrompe e va in stato ERROR.
Selezionando Fork in case of Error si creano due rami, uno eseguito se l'esecuzione del job va a buon fine (indipendentemente dal risultato) e l'altro eseguito se l'esecuzione del job va in errore (in tal caso l'esecuzione della pipeline non viene interrotta).
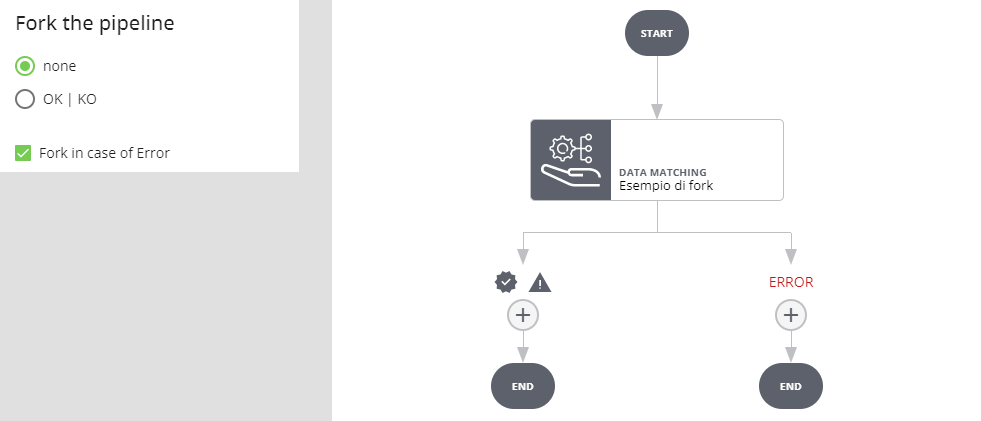
Fork in caso di OK | KO
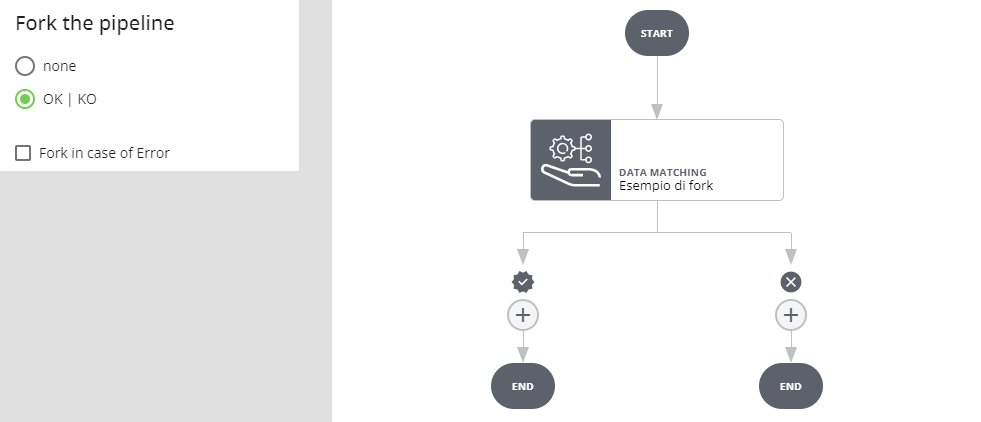
Se l'esecuzione del job va a buon fine e l'esito è positivo si prosegue per il ramo OK, se l'esito è negativo per il ramo KO. Se l'esecuzione del job va in errore l'esecuzione dell'intera pipeline si interrompe e va in stato ERROR.
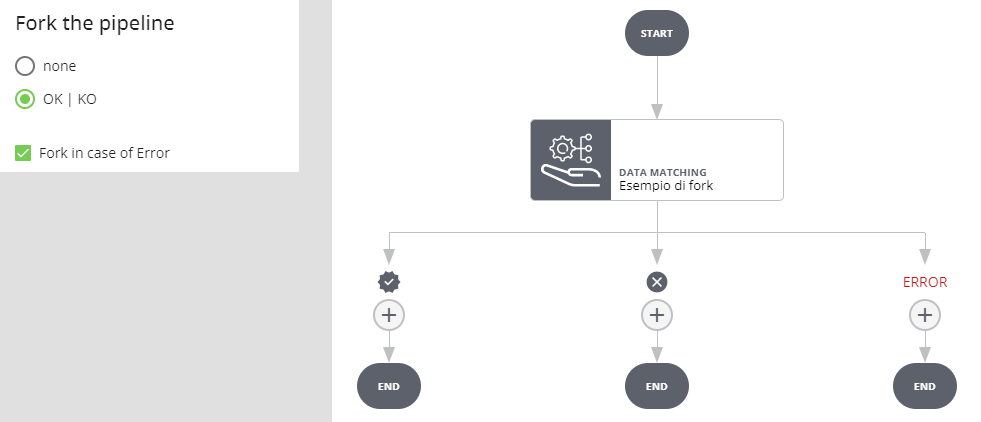
Selezionando Fork in case of Error si crea un ulteriore ramo: se l'esecuzione del job va a buon fine e l'esito è positivo si prosegue per il ramo OK, se l'esito è negativo per il ramo KO. Se l'esecuzione del job va in errore si procede per il ramo ERROR.
Fork per i job di Data Quality
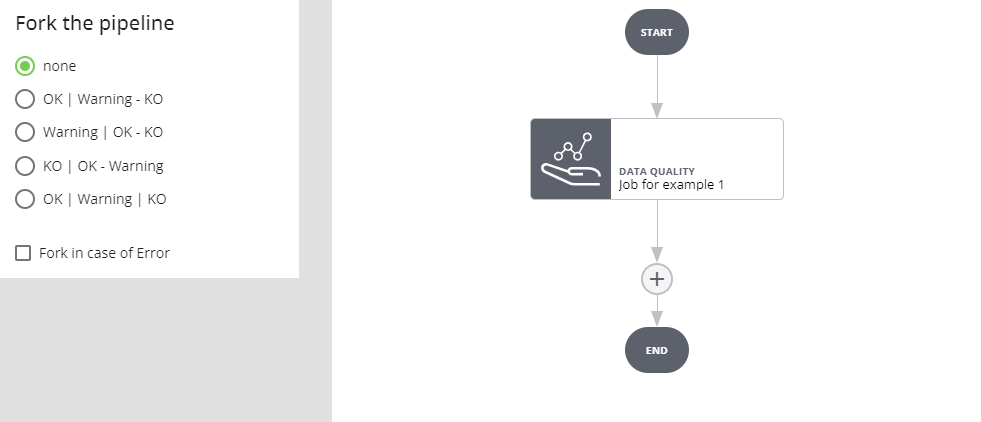
Nessun fork
In caso di errore nell'esecuzione del job l'esecuzione della pipeline si interrompe e va in stato ERROR.
Selezionando Fork in case of Error si creano due rami, uno eseguito se l'esecuzione del job va a buon fine (indipendentemente dal risultato) e l'altro eseguito se l'esecuzione del job va in errore (in tal caso l'esecuzione della pipeline non viene interrotta).
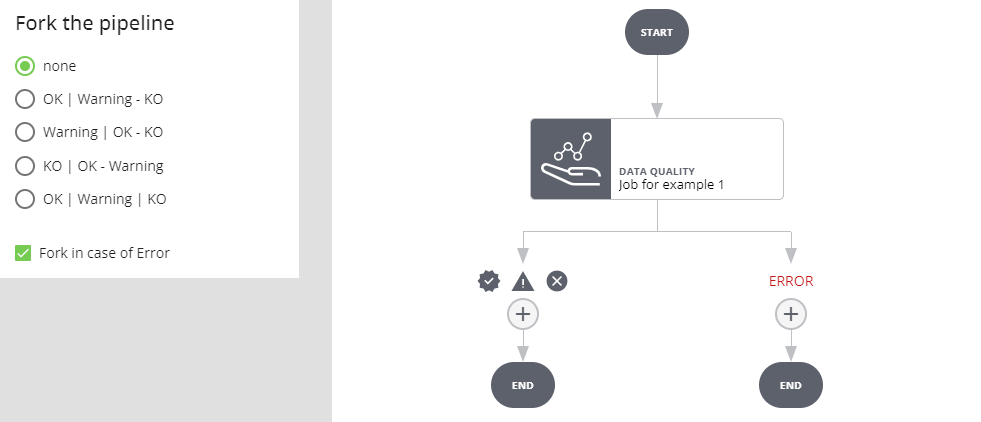
Fork in caso di OK
Se l'esecuzione del job va a buon fine e l'esito è positivo si prosegue per il ramo OK, se l'esito è warning o negativo si procede per l'altro ramo. Se l'esecuzione del job va in errore l'esecuzione dell'intera pipeline si interrompe e va in stato ERROR.
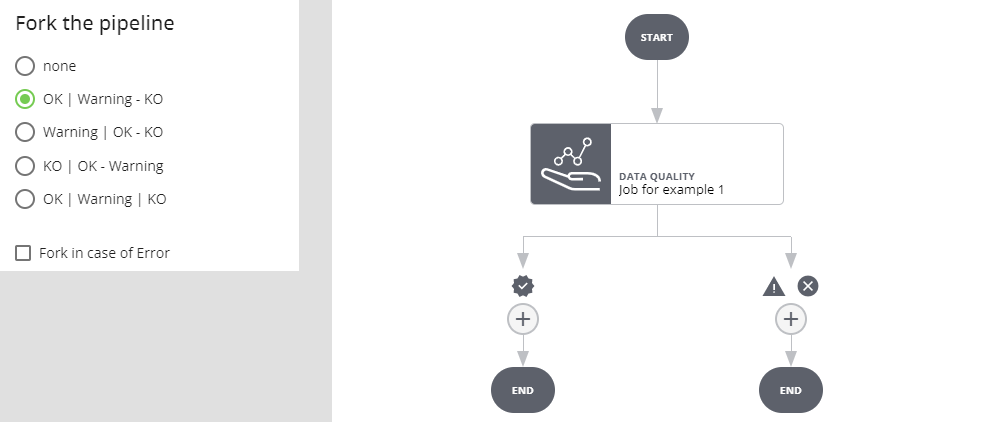
Selezionando Fork in case of Error si crea un ulteriore ramo: se l'esecuzione del job va a buon fine e l'esito è positivo si prosegue per il ramo OK, se l'esito è warning o negativo per il ramo WARNING/KO. Se l'esecuzione del job va in errore si procede per il ramo ERROR.
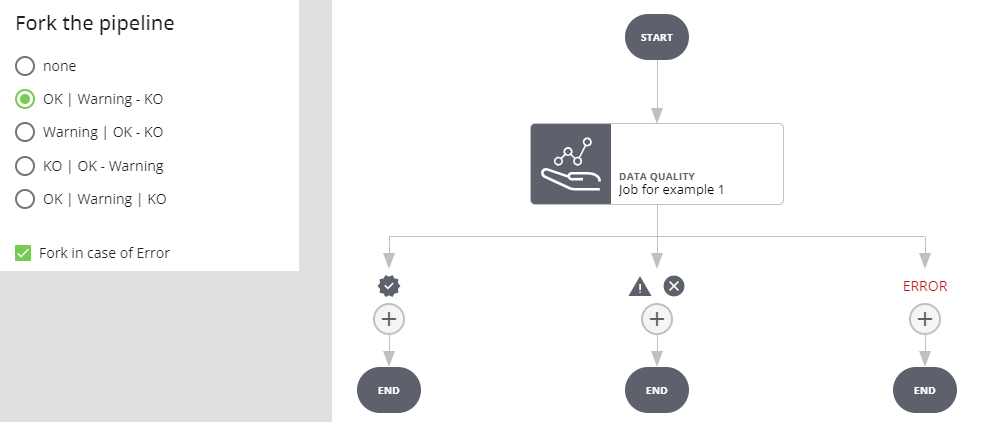
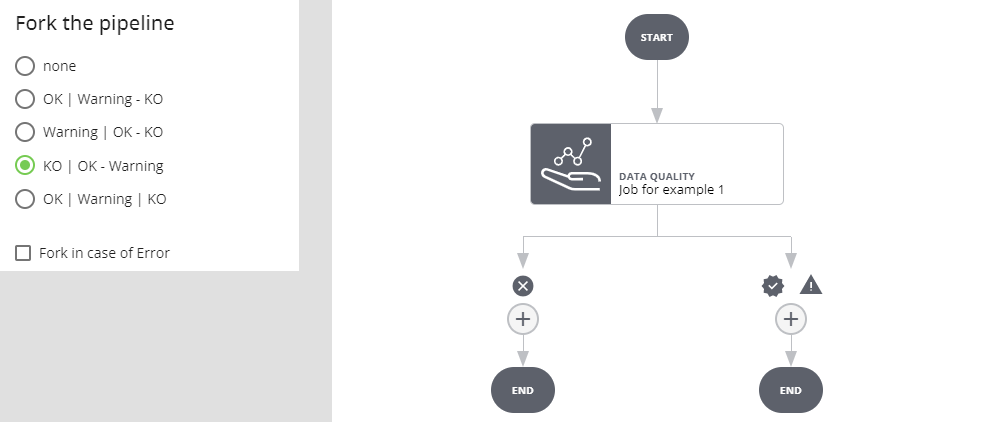
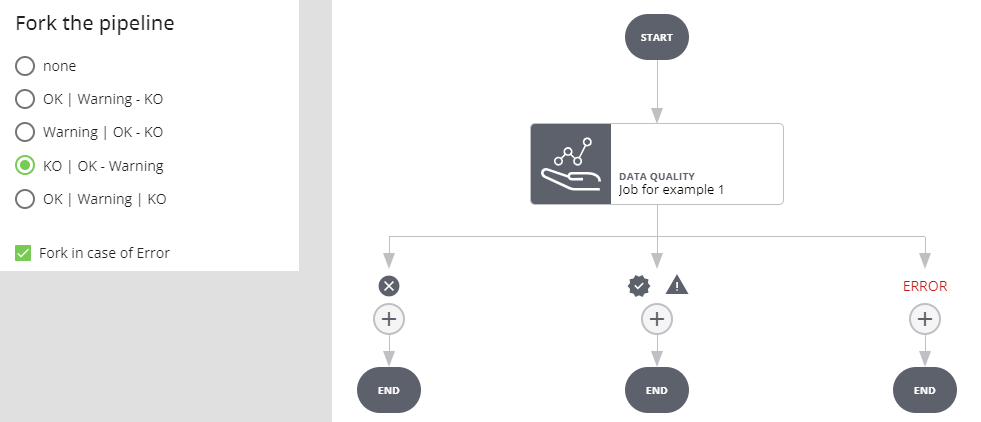
Fork in caso di Warning
Se l'esecuzione del job va a buon fine e l'esito è warning si prosegue per il ramo WARNING, se l'esito è positivo o negativo si procede per l'altro ramo. Se l'esecuzione del job va in errore l'esecuzione dell'intera pipeline si interrompe e va in stato ERROR.
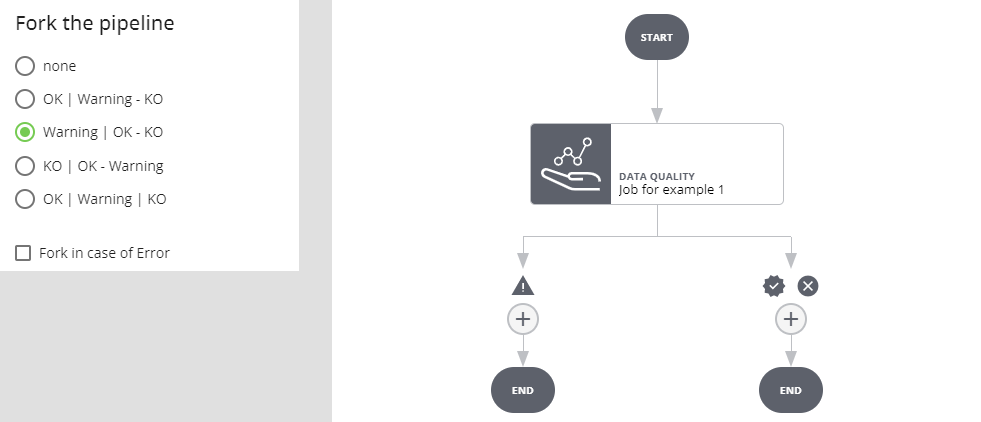
Selezionando Fork in case of Error si crea un ulteriore ramo: se l'esecuzione del job va a buon fine e l'esito è warning si prosegue per il ramo WARNING, se l'esito è positivo o negativo per il ramo OK/KO. Se l'esecuzione del job va in errore si procede per il ramo ERROR.
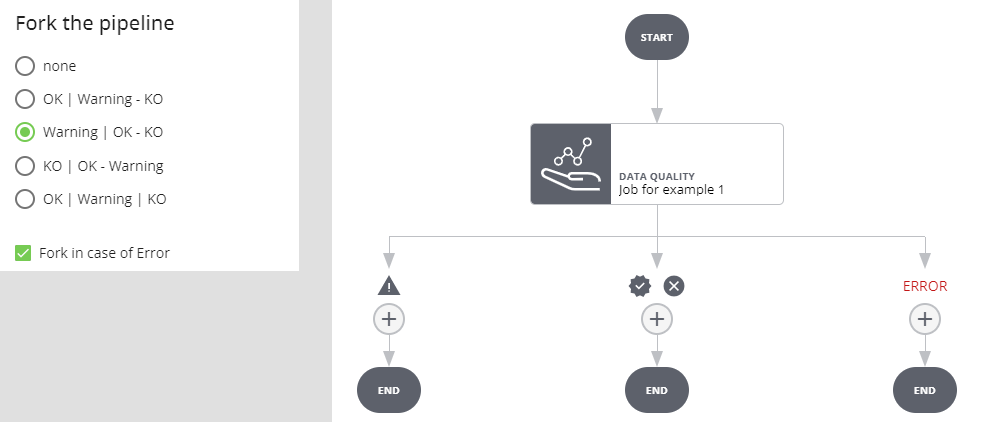
Fork in caso di KO
Se l'esecuzione del job va a buon fine e l'esito è negativo si prosegue per il ramo KO__, se l'esito è positivo o warning si procede per l'altro ramo. Se l'esecuzione del job va in errore l'esecuzione dell'intera pipeline si interrompe e va in stato _ERROR.
Selezionando Fork in case of Error si crea un ulteriore ramo: se l'esecuzione del job va a buon fine e l'esito è negativo si prosegue per il ramo KO, se l'esito è positivo o warning per il ramo OK/WARNING. Se l'esecuzione del job va in errore si procede per il ramo ERROR.
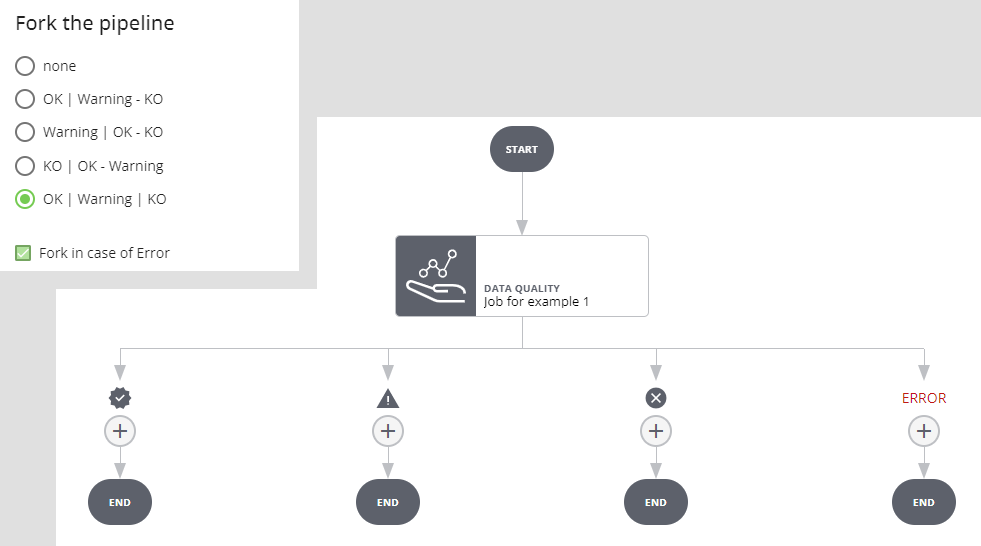
Fork in caso di OK, Warning e KO
In questo caso si creano tre rami distinti per i tre possibili esiti del job. Se l'esecuzione del job va in errore l'esecuzione dell'intera pipeline si interrompe e va in stato ERROR.
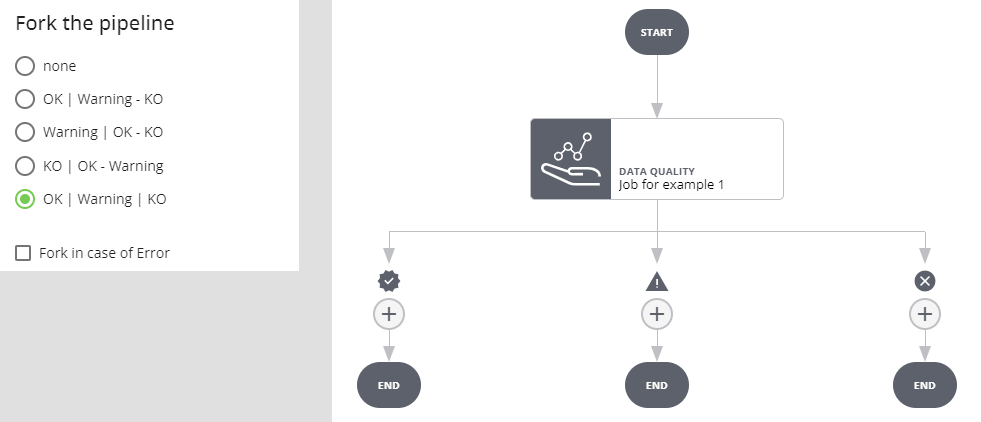
Selezionando Fork in case of Error si crea un ulteriore ramo: se l'esecuzione del job va in errore si procede per il ramo ERROR.
Eliminazione e disabilitazione di un job
È possibile eliminare un job (previa conferma) cliccando sull'icona Delete della sua interfaccia di configurazione: il job verrà eliminato dalla pipeline insieme a tutti i suoi discendenti.
È possibile disabilitare o riabilitare un job tramite lo switch Enabled:
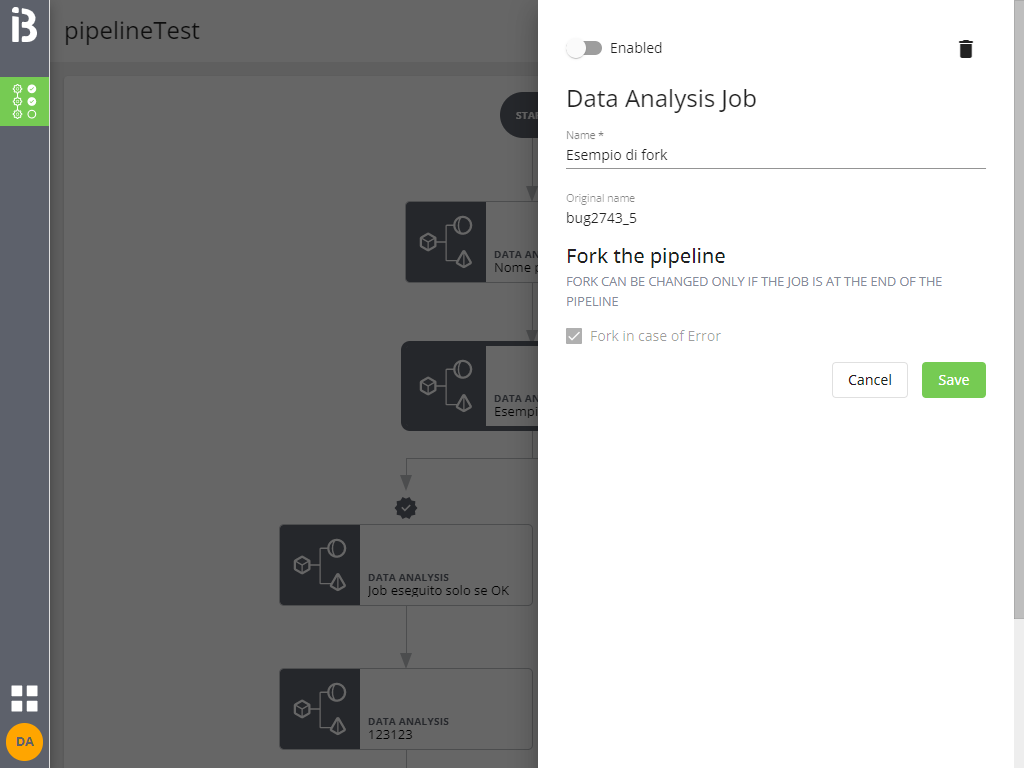
Un job disabilitato non viene eseguito e in caso di biforcazioni il flusso procede sempre nel ramo OK.
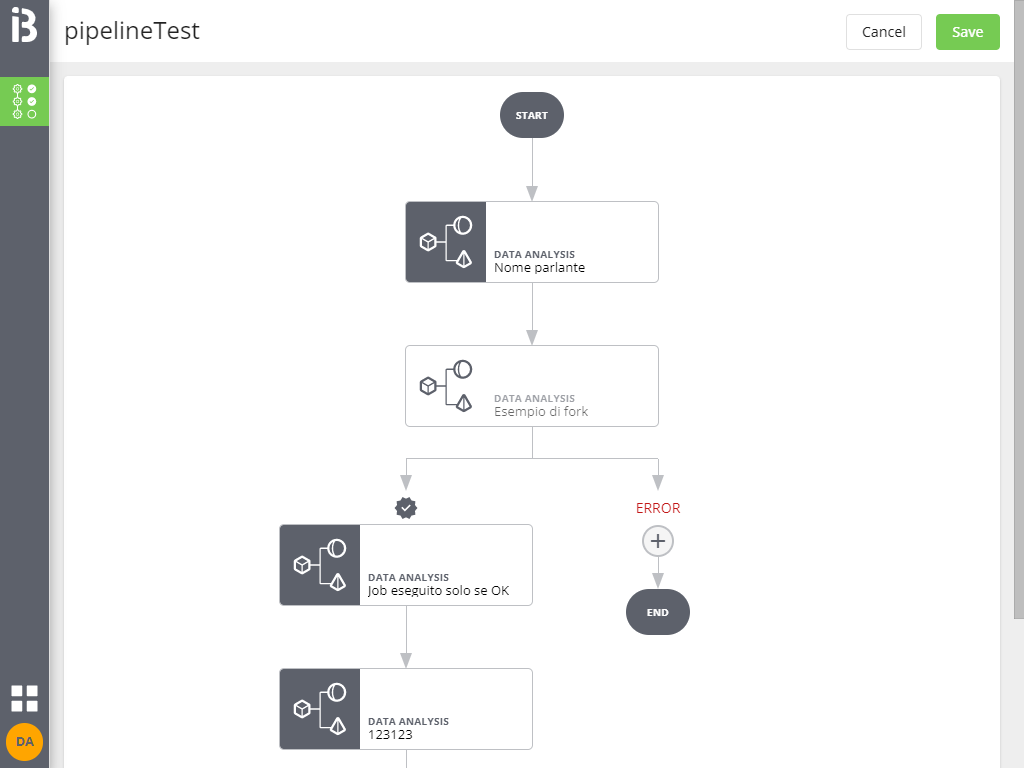
Salvataggio pipeline
Warning
Tutte le modifiche fatte in questa fase non hanno effetto finché non si salva la pipeline (pulsante Save in alto). Non è possibile salvare se la pipeline non contiene almeno un job.
Cliccando su Save in alto compare ancora una finestra in cui si chiede di configurare la schedulazione della pipeline (il default, Manually, indica che la pipeline non è schedulata e dovrà pertanto essere lanciata manualmente). La schedulazione è comunque modificabile in seguito.
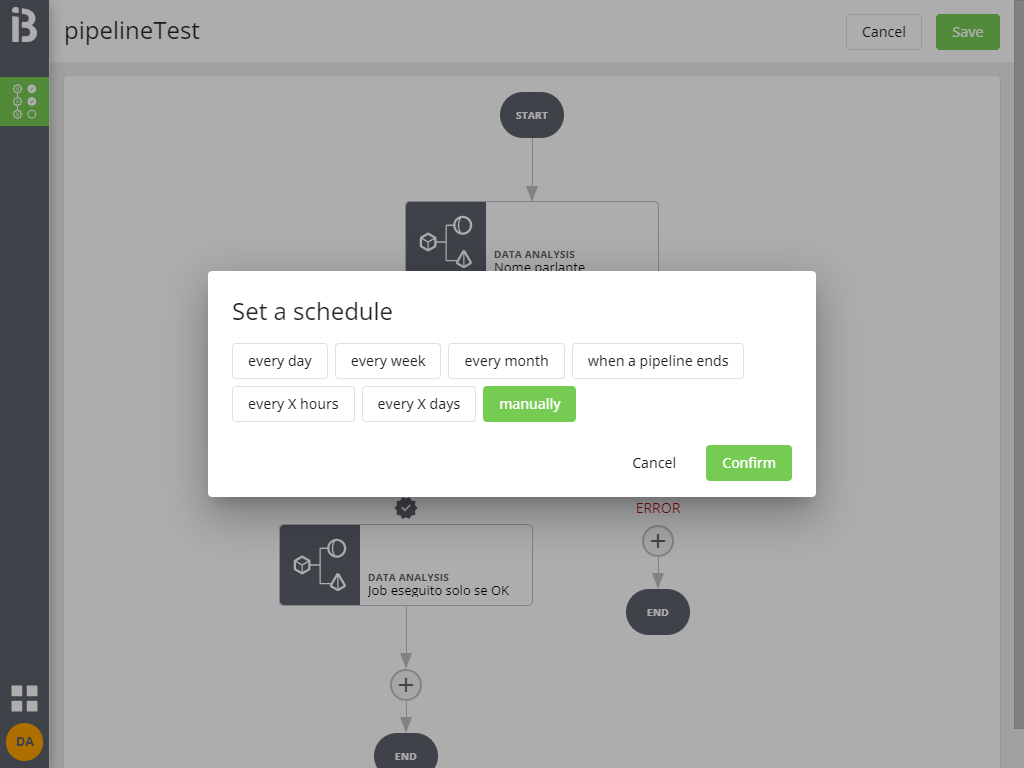
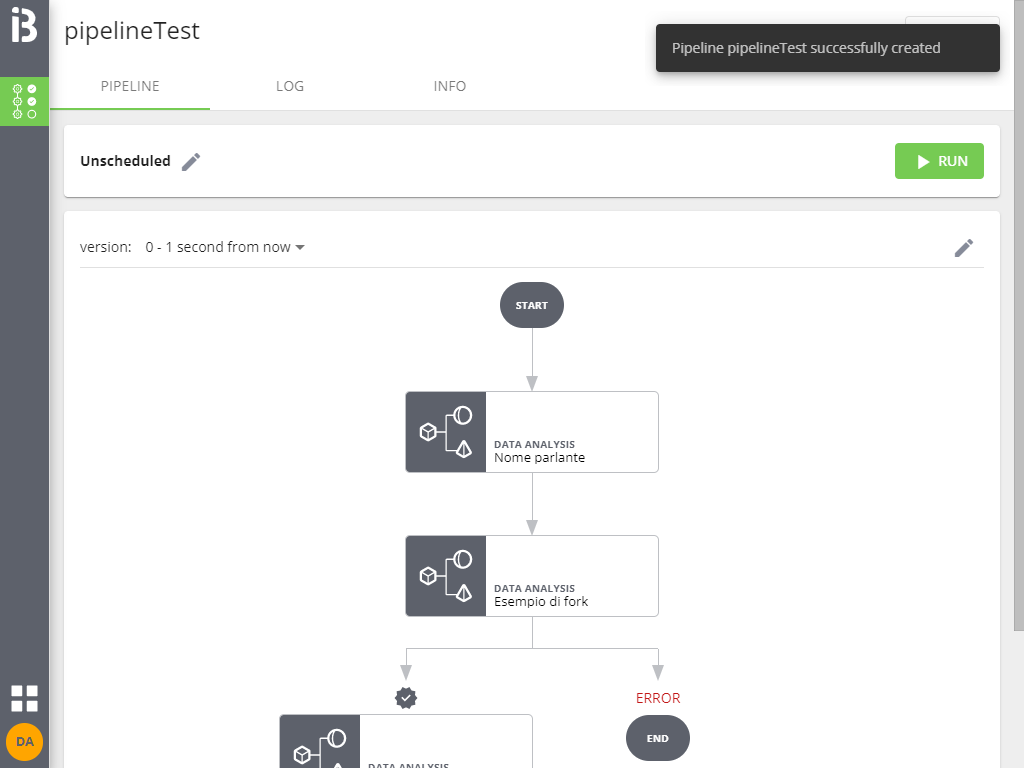
Cliccando su Continue si completa il salvataggio e si carica il dettaglio della pipeline appena creata: